Site Reliability Engineering (SRE) merges software engineering with IT operations to ensure software systems are reliable, scalable, and efficient. As modern systems become more complex, integrating DevOps practices with AI technologies is increasingly vital to boost reliability, performance, and scalability further.
SREs are responsible for maintaining high system uptime, minimizing manual repetitive work (toil) through automation, managing incidents, and ensuring systems are observable and can scale with demand. This discipline demands expertise in automation (a core DevOps principle), systems thinking, software development, performance tuning, and rapid incident response.
By leveraging AI, SREs can move from reactive to proactive operations. AI enables predictive analytics, anomaly detection, and automated incident management, which helps anticipate and prevent issues before they impact users. This shift reduces downtime, optimizes resource use, and ensures systems remain robust as they grow in complexity.
Foundational DevOps Practices for Scalable SRE
DevOps emphasizes automation, continuous integration/continuous delivery (CI/CD), monitoring, and infrastructure as code (IaC), all of which form the backbone of Site Reliability Engineering (SRE). These practices not only accelerate software delivery but also ensure that systems are resilient, scalable, and observable by design.
A strong DevOps practice rests on several key pillars:
- Continuous Integration and Continuous Deployment (CI/CD): Automating the merging of code changes and their subsequent deployment to production environments accelerates development cycles, minimizes integration complexities, and leads to more dependable software releases. Tools like Jenkins and GitHub Actions are commonly used to orchestrate these CI/CD workflows, ensuring fast, reliable deployments.
- Monitoring and Health Checks: Continuously tracking application and infrastructure metrics ensures systems remain healthy and performant. Proactive monitoring, paired with automated health checks, enables early detection of anomalies, supports rapid incident response, and provides critical insights for ongoing optimization. Observability tools such as Prometheus, Grafana, and the ELK stack offer real-time system health insights.
- Infrastructure as Code (IaC): Managing and provisioning infrastructure using machine-readable configuration files instead of manual processes ensures consistency, promotes scalability, and enables version control for infrastructure management. Tools like Terraform and AWS CloudFormation help create reproducible, error-resistant infrastructure environments.
- Containerization and Orchestration: Employing technologies like Docker and Kubernetes packages applications with their dependencies into containers, guaranteeing environment consistency. Kubernetes further automates the deployment, scaling, and management of these containerized applications. This combination is foundational to building scalable, resilient systems.
Automation of Repetitive Tasks: Automating routine operations such as testing, deployment, and monitoring diminishes human errors and frees up valuable resources for more strategic initiatives. Common approaches include scripting with Python or Bash, and using configuration management tools like Ansible to reduce toil across the software delivery lifecycle.
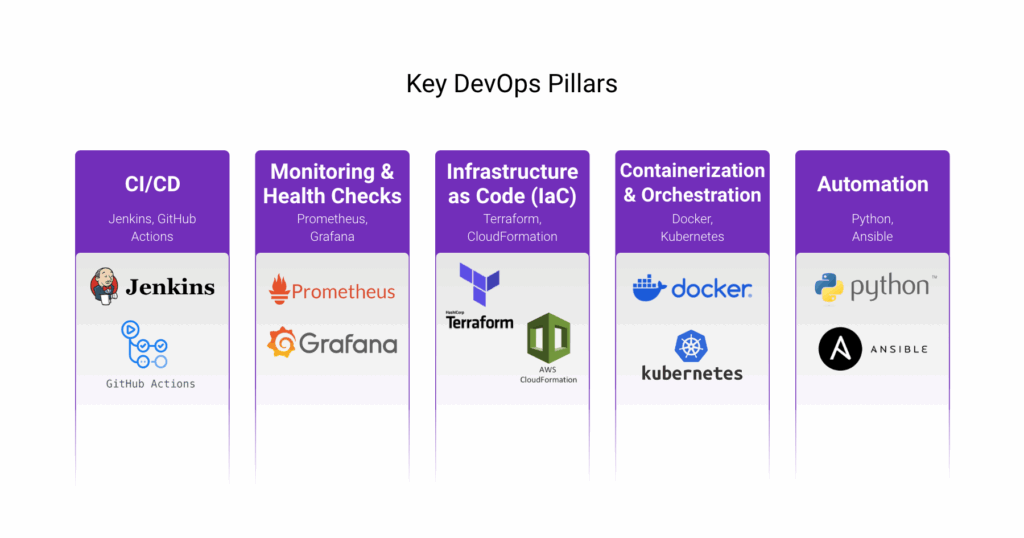
Together, these DevOps pillars form the operational foundation that automate reliability and allow SREs to manage modern, complex, distributed systems with agility and confidence. By embedding automation, standardization, and observability into the development lifecycle, SRE teams can proactively maintain system reliability, respond faster to incidents, and continuously improve performance at scale.
How AI Supercharges SRE: From Reactive to Proactive Operations
AI enhances SRE by transforming traditional operations into intelligent, proactive systems.
Here’s how:
- AI-Powered Monitoring and Anomaly Detection: AI models analyze historical metrics and logs to detect unusual patterns early, helping prevent downtime. Tools like Datadog APM, Dynatrace Davis AI, and AI-enhanced Prometheus surface anomalies before users are impacted.
- Intelligent Alerting: AI systems can intelligently filter out irrelevant alerts, prioritizing only those requiring immediate attention. This ensures DevOps teams focus on critical issues, improving response times and reducing alert fatigue.
- Predictive Analytics and Incident Prevention: By recognizing patterns in logs and user behavior, AI predicts incidents like database saturation or memory leaks, triggering autoscaling or preventive actions. This also ensures efficient allocation of resources, consistent performance during peak loads, and reduction of infrastructure costs.
- Automated Root Cause Analysis (RCA): Using platforms like Moogsoft and BigPanda, AI tools can automatically analyze logs and metrics to diagnose the underlying causes of incidents, providing faster insights compared to traditional methods.
- ChatOps and AI-driven Remediation: AI-powered chatbots integrated into communication tools like Slack or Teams enable SREs to run diagnostics, query system health, and execute automated runbooks, standardizing incident response and reducing mean time to recovery (MTTR).
- Continuous Improvement through Machine Learning: AI systems can learn from past incident data and human feedback to refine their models and improve future performance. This continuous learning cycle enhances system resilience and adaptability over time.
AI + DevOps in Action
Consider an e-commerce platform experiencing intermittent latency spikes during peak traffic hours.
Without AI: Engineers manually check dashboards across multiple services, shift through scattered logs, hold real-time war rooms to isolate the issue, and spend hours on root cause analysis. With AI + DevOps: Anomalies are automatically detected, alerts are deduplicated and enriched, and AI suggests probable causes, such as database connection pool exhaustion. SREs use ChatOps bots to apply automated fixes. The entire incident lifecycle is logged in real time, resulting in faster recovery, reduced toil, and improved uptime.

Getting Started: A Practical Path to AI-Enhanced SRE
Integrating AI into DevOps workflows within SRE is not about flipping a switch; it is about layering intelligence into existing processes with intention and clarity. A phased, iterative approach allows teams to test capabilities, measure impact, and build trust in AI-driven automation over time.
This is what we recommend:
- Start with AI-Powered Monitoring Tools: Implement tools that offer predictive analytics and anomaly detection to gain deeper insights into system performance.
- Experiment with Anomaly Detection and Intelligent Alerting: Utilize AI to identify unusual behavior and prioritize alerts, ensuring timely attention to critical issues.
- Explore Open-Source AI Tools or Python ML Models: Leverage open-source libraries and frameworks to develop custom AI models for alerts and remediation, tailoring solutions to your specific needs.
By thoughtfully integrating AI into your DevOps pipeline, you can amplify automation, strengthen system reliability, and cultivate a culture of continuous improvement.
Charting the Future of SRE
The future of SRE is autonomous operations, where systems self-monitor, self-heal, and self-scale. By combining DevOps automation with AI-driven intelligence, SREs can transition from firefighting to foresight. Start small, experiment often, and continuously evolve your practices to achieve operational excellence.
This approach aligns with evolving industry trends where AI enhances observability, incident management, and CI/CD pipelines, enabling SREs to optimize system reliability and efficiency in increasingly complex environments.