
Data extraction uses agents to autonomously retrieve structured and unstructured insights.
Data extraction refers to the automated retrieval of relevant information from raw, structured, or unstructured sources. In Agentic AI systems, this function is often performed by autonomous agents that operate across documents, APIs, databases, or even multimedia content.
Detailed Definition & Explanation
Data extraction is the first critical step in any intelligent workflow, especially in agent-led enterprise systems. It involves identifying, parsing, and structuring information from diverse inputs like scanned PDFs, spreadsheets, sensor data, HTML, APIs, or real-time telemetry. In Agentic AI, this process is embedded within intelligent micro-agents that don’t just extract data; they understand context, apply filters, and hand off structured payloads to downstream tasks like classification, reasoning, or decision-making.
Agents use techniques such as:
- OCR (Optical Character Recognition) for scanned documents
- Named Entity Recognition (NER) for unstructured text
- JSON/XML parsing for API responses
- Embedding-based retrieval for vectorized content
- Multimodal extraction when combining text, images, or audio inputs
Unlike static RPA scripts or brittle extraction logic, agentic data extraction adapts in real time, adjusting strategies based on content format, confidence thresholds, or policy constraints. This means agents can autonomously switch between extraction techniques and escalate when ambiguity or non-compliance is detected.
In agentic architectures, data extraction is tightly integrated with:
- Retrieval-Augmented Generation (RAG) pipelines
- Decision intelligence frameworks
- Dynamic policy validation
- Vector database indexing
This foundational layer powers everything from claims processing and legal contract review to real-time alerts in IT observability platforms.
Why It Matters
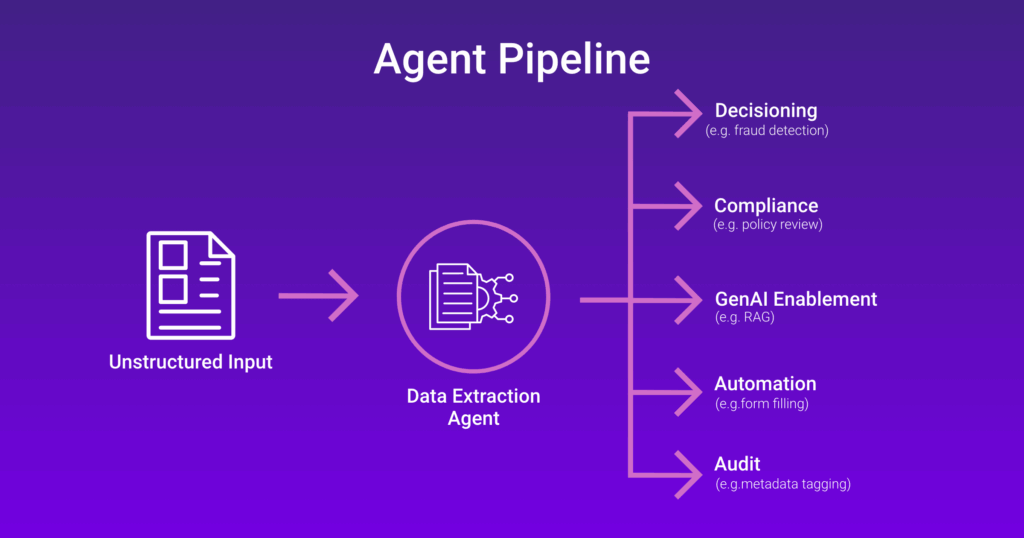
- Powers Context-Aware Decisioning
Agents extract real-time data (e.g., market prices, error logs, customer inputs) and pass it to downstream systems for classification, scoring, or reasoning. In the banking sector, this can enable fraud-detection agents to act on live transaction streams.
- Enables Scalable Compliance
Agents autonomously extract clauses or red flags from contracts, insurance policies, or audit logs. In legal or insurance industries, this supports large-scale regulatory reviews with minimal human effort.
- Feeds RAG and LLM Pipelines
Data extraction enables agents to surface relevant knowledge snippets from enterprise corpora, enhancing generative AI outputs. In higher education, agents can extract syllabus material to personalize tutoring sessions.
- Automates Manual Data Entry
Structured data is auto-extracted from invoices, receipts, or forms, reducing repetitive work. In an industry like ecommerce, this allows onboarding agents to auto-populate product catalogs from supplier sheets.
- Improves Data Trust and Traceability
Agents extract with metadata—source origin, time stamp, extraction logic—creating traceable, auditable records. This is essential in healthcare and financial services where data lineage is mandated.
Real-World Examples
Google Document AI
Google’s Document AI suite includes agent-like capabilities that parse, extract, and structure information from scanned documents using OCR, ML-based parsing, and layout understanding. It supports industries like lending and logistics.
FD Ryze
FD Ryze deploys autonomous data extraction agents for insurance claims intake, supplier onboarding, and compliance documentation. These agents interpret forms, extract structured entities, and integrate extracted payloads into orchestration workflows with policy checks and audit trails.
Instabase
Instabase uses pre-trained and fine-tuned AI models for enterprise-scale document processing. It enables use cases such as income verification, invoice reconciliation, and KYC processing using AI-based extraction and validation flows.
What Lies Ahead
1. Adaptive Multimodal Extraction
Future agents will combine vision, NLP, and audio processing to extract information across formats. For instance, extracting spoken clauses from video or visual annotations from blueprints. This will require advances in cross-modal fusion models and lightweight multimodal inference engines. Enterprises must invest in labeling strategies and annotation tools that support mixed-media training data.
2. Domain-Specific Extractors
Industry-tuned agents will emerge for healthcare, insurance, and legal domains, pre-loaded with templates, ontologies, and benchmarks for context-aware extraction. These extractors will use fine-tuned LLMs and schema-aware parsing frameworks to understand vertical-specific entities. Organizations should standardize internal taxonomies and metadata layers to improve extraction precision.
3. Embedded Extraction in GenAI Workflows
LLMs will collaborate with extractors via chain-of-thought prompting and self-verification to ensure the accuracy of sourced data within generative applications. Agent pipelines will evolve to include extraction-validation loops, using internal retrieval + LLM co-pilots for fact-checking. This will drive improvements in RAG pipelines, legal document drafting, and scientific knowledge generation.
4. Edge-Based Extraction
Data extraction agents will operate on-device in low-bandwidth or field environments, which is ideal for logistics, retail, and public infrastructure inspections. Tech stacks will involve quantized models, offline OCR, and edge-optimized hardware like NVIDIA Jetson or Apple Neural Engine. Companies will need hybrid cloud-edge strategies to synchronize extracted data with central systems without latency.
5. Policy-Aware Extraction
Agents will be integrated with OPA (Open Policy Agent) or similar frameworks to block, redact, or escalate extraction based on sensitive content, jurisdiction, or role permissions. Agents will enforce extraction policies at runtime, using metadata-tagged rules and permissioned logic trees. This is critical in sectors like healthcare, government, and banking where data access is tightly regulated.

Related Terms
- Intelligent Document Processing (IDP)
- OCR (Optical Character Recognition)
- Retrieval-Augmented Generation (RAG)
- Named Entity Recognition (NER)
- Enterprise Knowledge Graph
- Data Pipeline Automation
- Document AI