From Legacy Batch Exports to Real-Time Analytics: A Modern Data Foundation in Microsoft Fabric
<10 min
Data availability latency
(was 8–24 hrs)
Fabric Bronze
Foundation created for analytics, BI, and AI.
Eliminated
Dependency on legacy process
Automated
Replay capability for failed loads
<10 min
Data availability latency
(was 8–24 hrs)
Eliminated
Dependency on legacy process
Fabric Bronze
Foundation created for analytics, BI, and AI.
Automated
Replay capability for failed loads
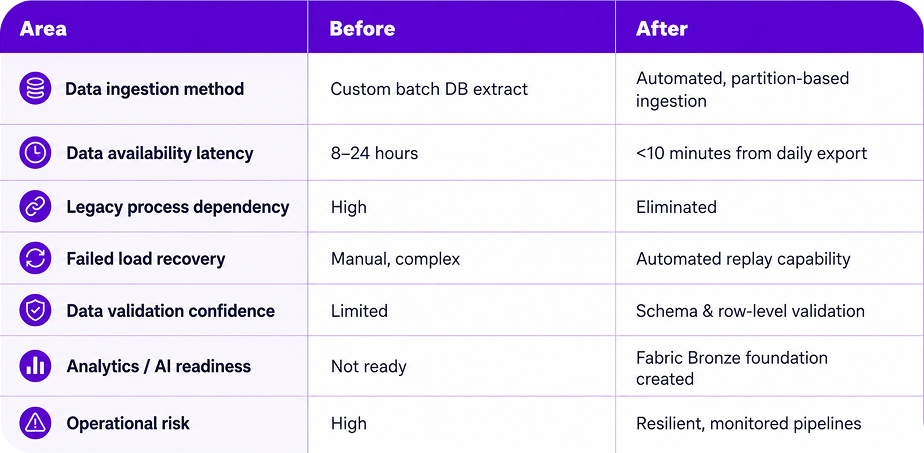
The Challenge
A System of Record Trapped Behind a Legacy Pipeline
The client’s warranty management platform served as the system of record but the way data flowed out of it constrained analytics and reporting downstream.
- Data extractions relied on a legacy batch process, introducing 8–24 hours of latency between when data was generated and when it became available for reporting.
- Reporting and downstream analytics placed indirect pressure on live operational systems, creating reliability risk around a mission-critical platform.
- There was no governed, scalable ingestion path into the organization’s Azure and Microsoft Fabric analytics environment, limiting trust in downstream data use.
Failed loads required manual recovery, validation was limited, and advanced use cases such as BI dashboards, fraud detection, and vendor performance analytics remained out of reach.
The Solution
A Governed Lakehouse Ingestion Framework
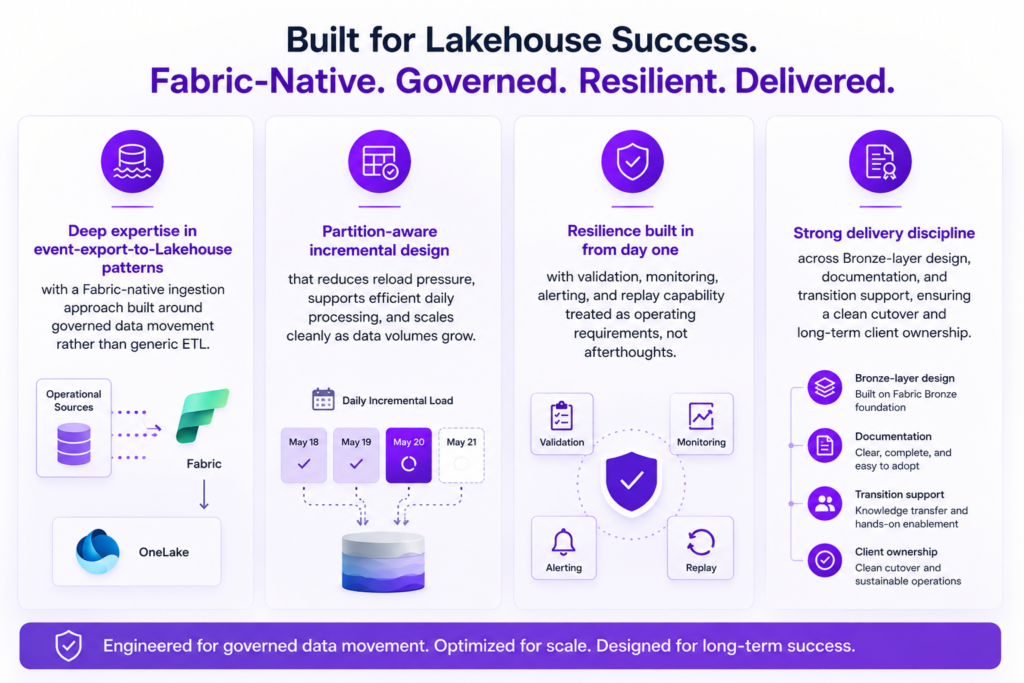
Fulcrum Digital designed and implemented a robust data ingestion framework connecting the client’s Kafka-based warranty data exports to Microsoft Fabric, replacing the legacy extraction process with a structured, automated, partition-aware pipeline.
Governed Bronze Layer
A single, trusted entry point for warranty data into the analytics environment, structured for Silver/Gold transformation and ready for BI, AI, and data science workloads.
Partition-Aware Incremental Ingestion
Historical and daily delta data processed automatically, with only new data ingested each run, eliminating redundant reloads and reducing system pressure.
Built-In Validation, Monitoring, & Replay
Schema and row-level validation, error handling, automated alerts, and replay capability built directly into the pipeline to ensure data completeness and reliability, alongside parallel verification against the existing process during transition.
Operational Readiness & Scalable Design
Comprehensive data mapping, runbooks, and documentation delivered to support client ownership, while the architecture was designed to onboard additional tables and topics with minimal effort.
Why Fulcrum
Don’t Just
Take Our
Word for It…
Let's Talk
Drop us your details and one of the Fulcrum team will reach out within one working day.
Let's Talk
Drop us your details and one of the Fulcrum team will reach out within one working day.