
The Five Architectural Checkpoints Every Bank Should Validate Before AI
Most banks are eager to scale AI, but very few pause to evaluate whether their data foundations can support it. The truth is, model accuracy, explainability, and speed don’t always fall apart because of algorithms. Most often, they fall apart because of the data underneath them. And after years of legacy systems, patchwork integrations, and one-off data projects, even well-run institutions end up with blind spots they don’t see coming.
These issues show up in fraud checks that misfire, customer decisions that contradict each other, or dashboards everyone debates but no one trusts.
If you’re planning to scale AI beyond isolated pilots, these are the five checkpoints worth validating before you take the next step.
1. Your data is still arriving in batches
Most banks still run on nightly or hourly data refreshes. That worked fine when analytics meant monthly risk reports or quarterly compliance checks. It doesn’t hold up when you’re trying to run fraud models, credit scoring, AML, or customer decisioning in real time.
If your AI systems are being fed yesterday’s data, you’re not realizing AI’s real-time potential. And in financial services, “recap mode” is where false positives multiply, fraud windows widen, and customer experiences lag.
Real-time AI needs streaming data, event triggers, and continuous ingestion. Without it, even the smartest models behave like they’re looking in the rearview mirror.
Fix:
- Introduce event-driven ingestion and message queues
- Implement CDC (Change Data Capture) pipelines
- Move critical datasets from batch ETL to streaming frameworks
- Prioritize real-time data for high-risk, high-value use cases first
Fulcrum POV:
Most of our modernization work at Fulcrum Digital begins by helping banks shift a few high-value processes, such as fraud checks, payments, and onboarding, away from batch refresh cycles. Because we’ve seen many institutions struggle with batch-bound systems, our role is usually to introduce a small real-time bridge, whether that’s a lightweight API layer or one of Fulcrum’s DataBridge-style connectors, to ensure live data reaches the teams and agents that need it.
You can’t trace or trust where your data came from
Ask any bank where a specific number in a risk report originated, and you’ll usually hear: “Give us some time to check.” That’s a red flag.
AI reliability breaks down when you can’t explain lineage: what system the data came from, how it was transformed, and whether it’s compliant with internal policies and external regulations. And if governance sits in spreadsheets, SharePoint folders, or email threads, you’re guaranteed drift, duplication, and blind spots.
In regulated environments, untraceable data isn’t just an inconvenience but a model a governance gap that regulators will eventually surface.
Fix:
- Deploy an automated metadata catalog to make data discoverable and traceable
- Build end-to-end lineage tracking for critical datasets
- Reduce manual governance by adding policy-driven automation where possible
- Establish domain-level stewardship with clear ownership
Fulcrum POV:
One of the quickest wins in any modernization effort is simply restoring trust in the data itself. We typically start by tightening up auditability, making sure every action, transformation, and handoff is logged through FD Ryze’s governance layer and audit-ready controls. It’s a small shift, but it means teams always know what changed, who touched it, and why it matters.

Your data lake has turned into a swamp
Banks were early adopters of data lakes. A decade later, many of those lakes are now overgrown, under-maintained, and datasets with unclear ownership.
If analysts are spending more time hunting for the right table than using it, that’s a sign the lake is no longer helping you. AI depends on clean, catalogued, high-quality data. When a lake becomes a dumping ground of thousands of tables, few labels, even fewer stewards, AI development slows to a crawl.
You can’t build AI on top of a swamp; you end up paying for storage and rework instead of insights.
Fix:
- Assign data stewards to high-value domains
- Create tiered governance (critical, moderate, low-priority datasets)
- Introduce automated profiling and quality scoring
- Archive, deprecate, or quarantine unused or duplicate tables to reduce noise
Fulcrum POV:
Data swamps tend to form slowly, usually after years of uncoordinated ingestion and no clear ownership. Our work often starts by reorganizing that landscape: cleaning up redundancies, reconnecting data domains, and building the data management foundations that let downstream teams, dashboards, and AI agents finally work off consistent and governed inputs.
4. Your data contradicts itself across systems
In many banks, the same customer can show up with three different addresses, two different income levels, and multiple risk ratings depending on whether you pull data from the core banking system, CRM, risk system, or the lake.
That’s not so much a data problem as it is an architectural one: these systems were never designed to talk to each other, so each maintains its own version of the truth.
AI models assume consistency; contradictory data forces them to “average out” the truth or ignore important signals. Either way, accuracy drops and explainability suffers.
Fix:
- Use entity resolution to unify records across systems
- Create a golden record per customer with clear reconciliation rules
- Implement a master data layer (MDM)
- Standardize business definitions across teams
Fulcrum POV:
Contradictions usually come from years of systems evolving independently. Our teams focus on reconciling those versions by detecting mismatches early and linking entities across core banking, CRM, and risk platforms so the downstream view is consistent. Even that one step makes AI outputs cleaner, more explainable, and far easier to trust.
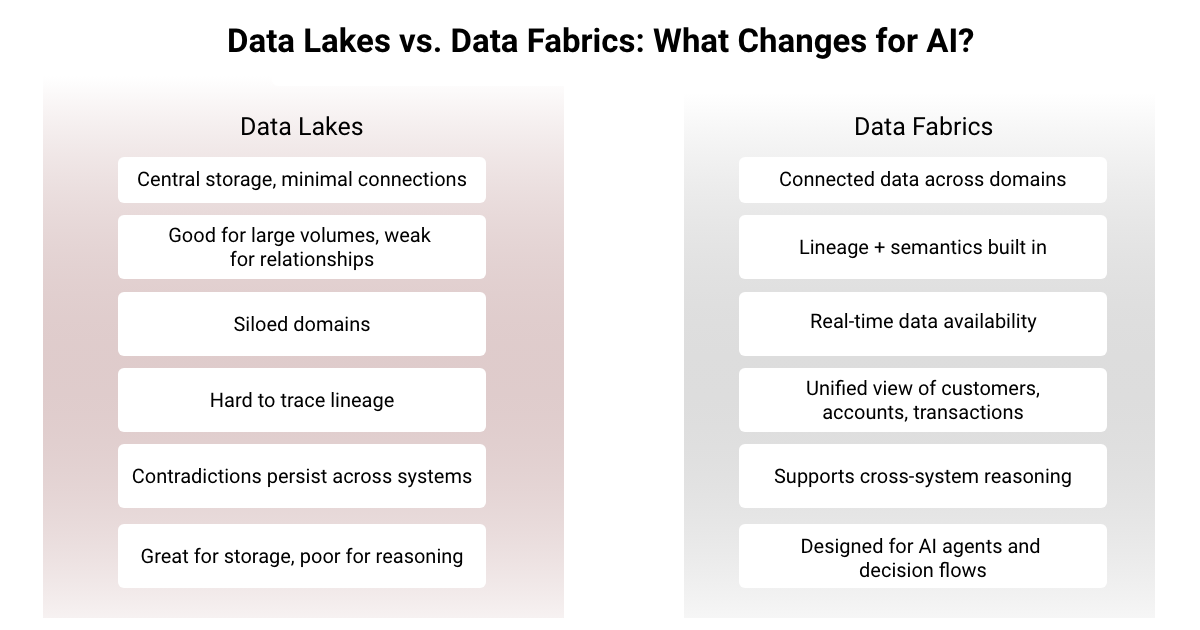
5. Your data has no context or shared meaning
Two banks can store the exact same transaction data and get completely different value from it. Why?
Context.
AI doesn’t need data alone; it needs meaning. It needs to know how a transaction relates to an account, how that account relates to a customer, and how that customer relates to risk exposure, AML rules, or behavioral patterns. Without semantic layers, ontologies, and relationship mapping, AI models are essentially reading raw data with no sense of the bigger story.
When your data lacks structure, relationships, and definitions, your AI becomes narrow, brittle, and siloed, no matter how advanced the model is.
Fix:
- Develop ontologies for key banking domains
- Introduce semantic tagging and business definitions
- Use knowledge graphs to map real-world relationships
- Align data models with real decision journeys (fraud, onboarding, credit, etc.)
Fulcrum POV:
When data lacks context, AI behaves as if it’s processing isolated fields rather than understanding customer context. We fix that by building the connective tissue: linking customers, accounts, transactions, and risk indicators through FD Ryze’s entity comprehension features like proprietary knowledge graphs and semantic reasoning. It’s a small structural shift that gives AI agents the context they need to reason instead of react.
If you want to understand where your data architecture stands today, we’d be happy to help. Reach out to us at Banking & Financial Services – Fulcrum Digital and we’ll help you diagnose what’s slowing AI down.



